
La base de datos más amplia del mundo para aprender español
Investigadores de la Universidad de Granada han desarrollado una aplicación web llamada CEDEL2 (Corpus Escrito del Español como segunda lengua), que nace para dar respuesta a la necesidades investigadoras y docentes del español como lengua extranjera a nivel internacional.
Investigadores de la Universidad de Granada (UGR) dirigidos por el profesor Cristóbal Lozano, han desarrollado una aplicación web llamada CEDEL2 (Corpus Escrito del Español como segunda lengua), que nace para dar respuesta a la necesidades investigadoras y docentes del español como lengua extranjera a nivel internacional.
CEDEL2 es un corpus lingüístico de aprendices de español, es decir, una gran base de datos que contiene el lenguaje producido por aprendices de español (personas que están aprendiendo español como su segunda lengua). Contiene, además, el lenguaje de hablantes nativos de español de España y de otras variedades de Latinoamérica (Méjico, Argentina, Colombia, etc.). De esta forma, los investigadores usan los datos de los nativos de español como referencia para ver si el lenguaje de los aprendices se acerca (o se aleja) del lenguaje de los nativos.
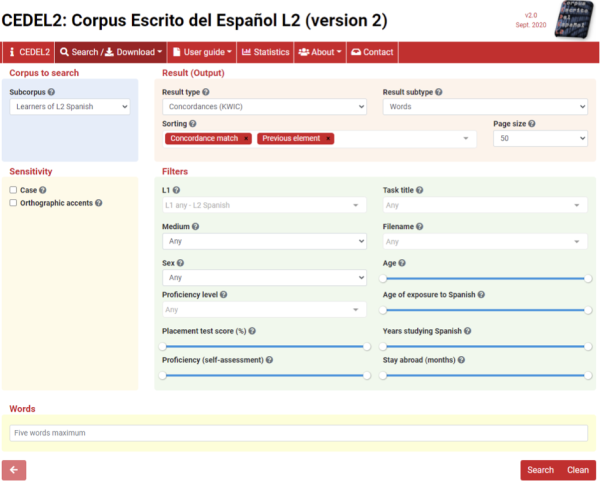
Interfaz web de CEDEL2 (motor de búsqueda).
Por ejemplo, es bien sabido que los aprendices cometen errores básicos de concordancia entre el artículo y el nombre: “la clima”, “la problema”. CEDEL2 es una herramienta informática potentísima que sirve a los investigadores de “ventana” para comprender cómo funciona el lenguaje en la mente de los aprendices. Asimismo, los docentes de español pueden usarlo en clase para que los estudiantes exploren y aprendan de los errores cometidos por otros aprendices como ellos.
CEDEL2 es gratuito, y está alojado en el portal web cedel2.learnercorpora.com. La aplicación informática cuenta con un potente buscador y una interfaz intuitiva y accesible. Ofrece múltiples posibilidades para la investigación y la docencia. Permite hacer tanto búsquedas sencillas de palabras como búsquedas de estructuras lingüísticas complejas. Las búsquedas y los textos completos se pueden descargar para analizarlos posteriormente. Además de textos escritos, CEDEL2 contiene grabaciones orales. Ya se han llevado a cabo más de medio centenar de estudios internacionales y tesis doctorales con datos procedentes de CEDEL2.

Los investigadores del IberLab de la Universidad de Granada que han realizado este trabajo.
El corpus tiene una larga trayectoria pues lleva en desarrollo desde el año 2006 y ha sido financiado por numerosos proyectos de investigación I+D nacionales, como el último proyecto ANACOREX. En CEDEL2 ha colaborado un equipo internacional de 30 investigadores procedentes de 11 universidades. Dado este carácter internacional, CEDEL2 incluye datos de aprendices de español de hasta 11 lenguas maternas distintas (y muy variopintas), como el inglés, japonés, chino, árabe, ruso, alemán, etc. Actualmente, la segunda versión del corpus contiene el lenguaje producido por unos 4.400 hablantes y más de 1 millón de palabras, lo que lo convierte en el corpus más extenso de su categoría.
CEDEL2 está en constante crecimiento y los investigadores siguen recogiendo datos para la futura 3ª versión del corpus. Cualquiera puede participar en el corpus CEDEL2 a través de su portal web (learnercorpora.com). Sólo hay que escribir/narrar una breve historia en español y proporcionar información sobre el perfil lingüístico. La participación está remunerada.
Paralelamente, el equipo también ha desarrollado un corpus de inglés como lengua extranjera: COREFL (Corpus of English as a Foreign Language), que sigue los mismos principios de diseño que CEDEL2, lo que permite hacer múltiples comparaciones del lenguaje producido por, por ejemplo, nativos de español que aprenden inglés (COREFL) vs. nativos de inglés que aprenden español (CEDEL2). COREFL está disponible gratuitamente en la web (corefl.learnercorpora.com).
Logotipo de CEDEL2.
En definitiva, este proyecto es una aportación innovadora en el ámbito de la lingüística, el bilingüismo, el aprendizaje de lenguas y las humanidades digitales.
Más información:
Aplicación online de CEDEL2: learnercorpora.com
Portal web para participar: learnercorpora.com
Video promocional de CEDEL2: https://wpd.ugr.es/~cristoballozano/divulgacion
Publicación científica: Lozano, C. (2021). CEDEL2: Design, compilation and web interface of an online corpus for L2 Spanish acquisition research. Second Language Research, first published online. https://doi.org/10.1177/02676583211050522


Suscríbete a nuestra newsletter
y recibe el mejor contenido de i+Descubre directo a tu email
